ポスト
ポスト


海外ジャーナルクラブ
4日前
【JAMA Dermatol】AI皮膚癌診断は中堅医に匹敵、10年超専門医には届かず
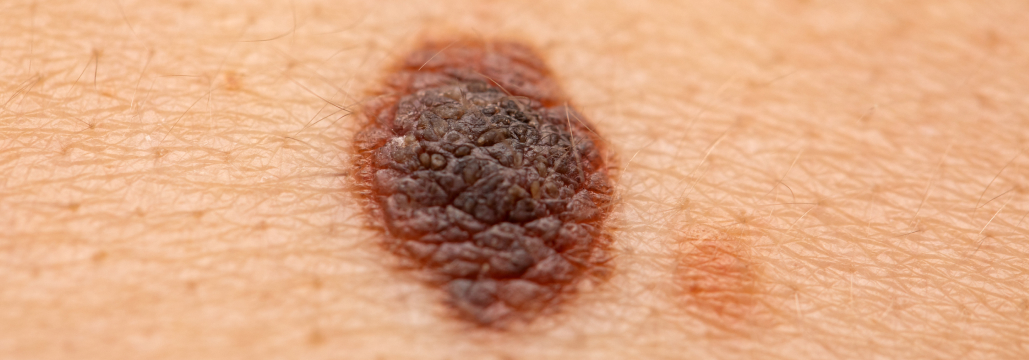
Anriotらは、 実臨床に近い設定での皮膚病変診断において、 AIモデル3種と、 1年未満~10年超の皮膚科経験医師の診断精度を多施設診断研究で比較した。 その結果、 最新の基盤モデルは経験3年未満の医師を上回ったが、 経験10年超の専門医には及ばなかった。 なお、 経験10年超の読影者の診断精度は平均74.2%で、 全AIモデルを上回った。 試験結果はJAMA Dermatol誌に発表された。
📘原著論文
👨⚕️HOKUTO監修医コメント
本データセットは主に教育目的で構築されたため、 診断が難しい症例や視覚的特徴が明瞭な症例が選択されるバイアスが存在した可能性があります。
関連コンテンツ
解説 : 近畿大学医学部皮膚科学教室 大塚篤司 先生
背景
皮膚癌AI診断は実臨床で性能低下
皮膚癌検出のAIシステムは、 日常臨床では性能が低下した。
本研究は、 稀少・非典型例を含む皮膚病変診断について、 実臨床に近い文脈で、 AIと専門性レベルの異なるヒト評価者の精度を比較した。
研究デザイン
AIモデル3種と医師の診断を比較
本多施設診断研究では、 経験1年未満~10年超の皮膚科経験を持つ医師読影者とAIモデルの診断性能を比較した。
日常臨床を反映した皮膚画像データセット1,117例 (臨床画像・ダーモスコピー画像とメタデータ) を用い、 以下のAIアルゴリズム3種の精度を比較した。
- 第1世代畳み込みニューラルネットワーク (CNN)
- PanDerm単一モダリティ基盤モデル
- PanDermマルチモダリティ基盤モデル
ヒト読影者は、 同データセットから層別抽出した100例を評価した。
主要評価項目は、 病変分類の多クラス診断精度とした。
結果
全ヒト読影者がCNNを上回る
652人の医師が1,092回評価を行った結果、 全ヒト読影者がCNNを上回った。
平均精度は、 ヒト読影者で65.9%、 AIで56.7% (差 9.2㌽ [95%CI -9.8~8.5㌽、 p<0.001])であった。
単一モダリティ基盤モデルは経験3年未満の医師を上回る
単一モダリティ基盤モデルの精度は経験3年未満の読影者を上回った。
平均精度は、 ヒト読影者で68.2%、 AIで72.2% (差 4.0㌽ [95%CI 3.2-4.9㌽、 p<0.001])であった。
経験10年超の医師は全AIを上回る
経験10年超の読影者は平均精度74.2%で最高の診断精度を達成し、 全AIモデル (CNN : 56.7%、 単一モダリティ : 72.2%、 マルチモダリティ : 66.3%) を上回った。
結論
基盤モデルは中堅医師に匹敵するが熟練専門医には及ばない
著者らは、 「最新の基盤モデルは経験3年未満の読影者を上回り経験3~10年の医師に匹敵したが、 経験10年超の専門医には及ばず、 皮膚科診断におけるAIの有望性と現状の限界の双方を浮き彫りにした」 と報告している。


編集・作図:編集部、 監修:所属専門医師。各領域の第一線の専門医が複数在籍。最新トピックに関する独自記事を配信中。

編集・作図:編集部、 監修:所属専門医師。各領域の第一線の専門医が複数在籍。最新トピックに関する独自記事を配信中。